
Deep Dive into Z-Image: The New Standard for Efficient & Versatile AI Image Generation
In the rapidly evolving landscape of generative AI, the balance between speed, quality, and computational efficiency is the holy grail. Today, we are excited to introduce the Z-Image (造相) project, a groundbreaking family of image generation models that not only challenges current benchmarks but redefines what open-source foundation models can achieve.
Built on a robust 6-billion parameter architecture, Z-Image offers a suite of variants tailored for everything from real-time inference to deep creative editing. Whether you are a researcher pushing the boundaries of diffusion transformers or a creator looking for the next best tool, here is everything you need to know about Z-Image.
The Z-Image Family: One Core, Four Specialized Variants
The Z-Image project isn't just a single model; it's a strategic ecosystem designed to address specific needs in the generative pipeline.
1. Z-Image-Turbo 🚀
The Speed Demon
Z-Image-Turbo is the distilled powerhouse of the family. Engineered for efficiency, it achieves state-of-the-art results with only 8 Number of Function Evaluations (NFEs).
- Performance: Sub-second latency on enterprise H800 GPUs.
- Accessibility: Fits comfortably within 16GB VRAM on consumer hardware.
- Strengths: Unmatched photorealism, precise instruction following, and superior bilingual text rendering (Chinese & English).

2. Z-Image (Foundation) 🎨
The Creative Engine
This is the undistilled, full-capacity foundation behind the Turbo variant. While Turbo is optimized for speed, the standard Z-Image is optimized for creative freedom.
- Key Features: High-quality aesthetic output, robust negative prompting, and diverse style coverage.
- Diversity: Generates highly varied outputs across identities, poses, and compositions, avoiding the "same-face" syndrome common in other models.
- Best For: Fine-tuning, downstream development, and artistic exploration.

3. Z-Image-Omni-Base 🧱
The Developer's Canvas
For the open-source community, Tongyi Z-Image released the Omni-Base, a versatile foundation capable of both generation and editing tasks.
- Purpose: To provide the most "raw" starting point for developers.
- Potential: Unlocks the full potential for community-driven fine-tuning, allowing users to build custom workflows from the ground up.

4. Z-Image-Edit ✍️
The Visual Editor
Fine-tuned specifically for image-to-image tasks, Z-Image-Edit understands complex natural language instructions to modify existing visuals.
- Capability: Precise edits based on prompts (e.g., "make it snowy," "change the background") without losing the structural integrity of the original image.

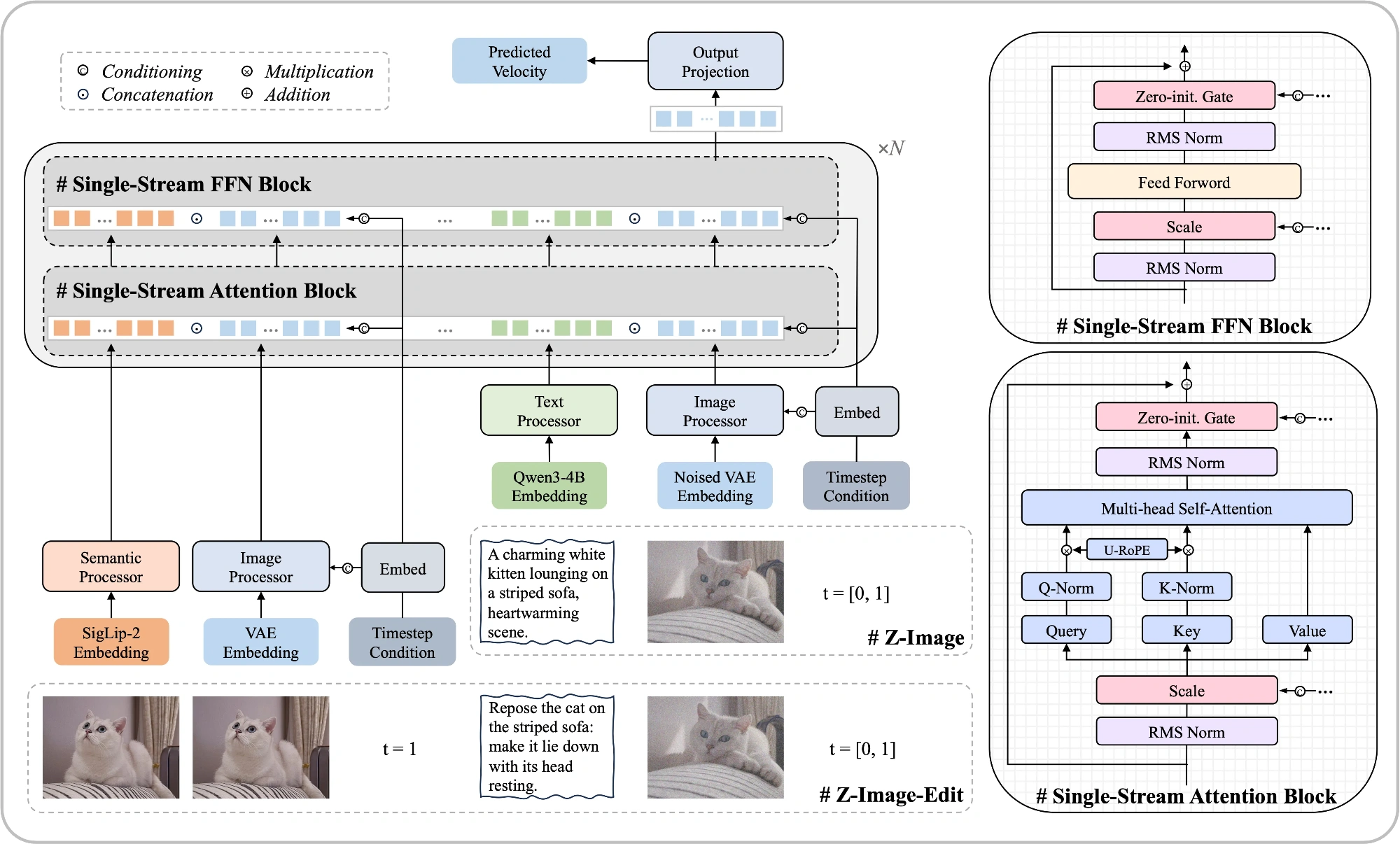
Innovative Architecture: Scalable Single-Stream DiT (S3-DiT)
At the heart of Z-Image lies the Scalable Single-Stream Diffusion Transformer (S3-DiT). Unlike traditional dual-stream architectures that process text and images separately, S3-DiT unifies the workflow.
- Unified Input Stream: Text tokens, visual semantic tokens, and image VAE tokens are concatenated at the sequence level.
- Efficiency: This design maximizes parameter efficiency, allowing the 6B model to punch above its weight class in terms of reasoning and generation quality.
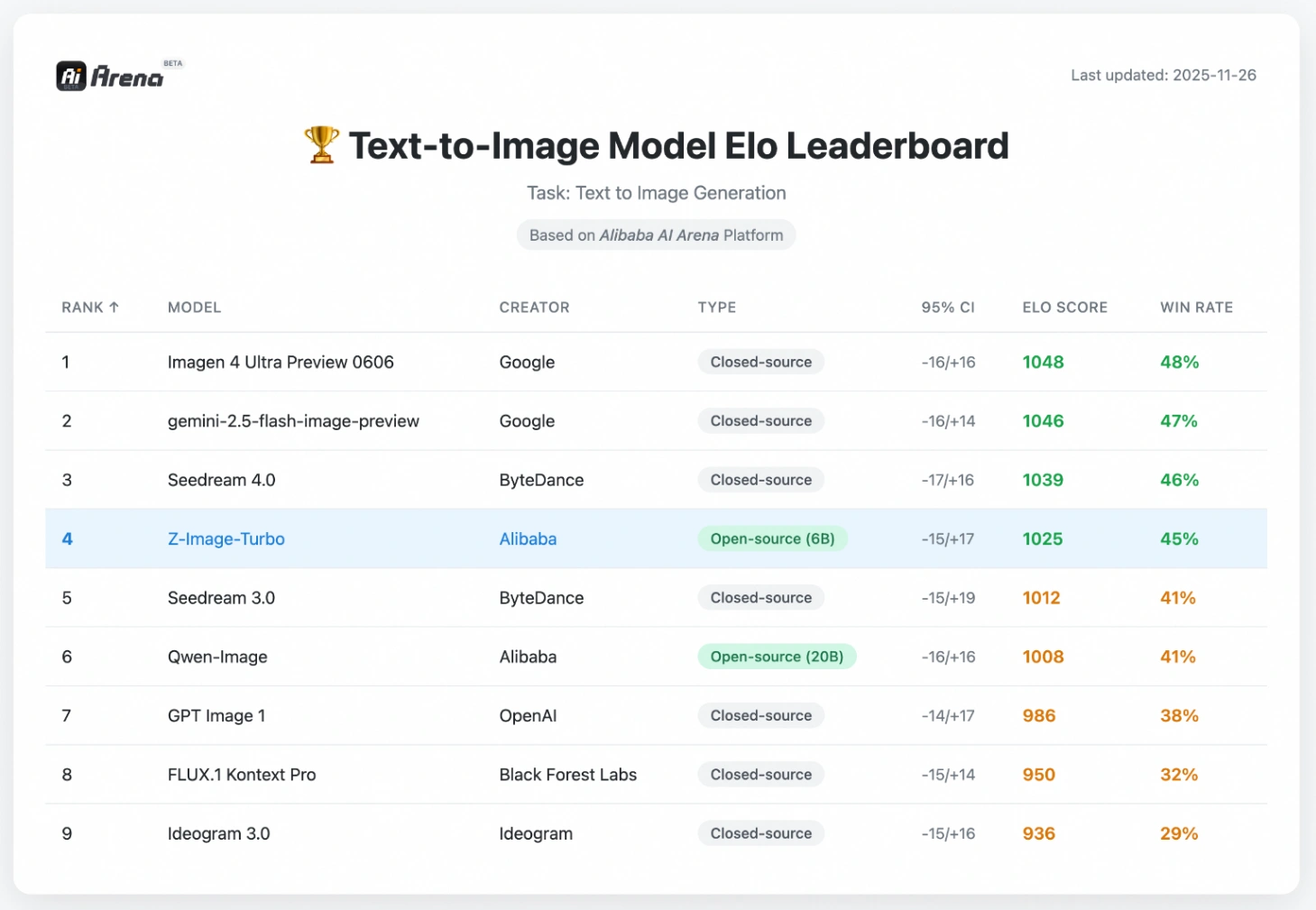
State-of-the-Art Performance
Z-Image-Turbo has already made waves in the industry, proving that open-source models can compete with—and beat—proprietary giants.
- #1 Open-Source Model: Ranked 1st among open-source models and 8th overall on the Artificial Analysis Text-to-Image Leaderboard.
- Human Preference: Achieved top-tier Elo ratings on the Alibaba AI Arena, validating its superior visual quality and prompt adherence in blind human tests.
The "Secret Sauce": Decoupled-DMD & DMDR
How does Z-Image-Turbo achieve such high quality in just 8 steps? The answer lies in our novel distillation techniques.
Decoupled-DMD
We discovered that Distribution Matching Distillation (DMD) succeeds due to two independent mechanisms:
- CFG Augmentation (CA): The engine driving the distillation.
- Distribution Matching (DM): The stabilizer ensuring quality. By decoupling these, we optimized them individually, resulting in the Decoupled-DMD algorithm that powers our efficient few-step generation.
DMDR: Fusing RL with Distillation
To further refine the model, we introduced DMDR, which integrates Reinforcement Learning (RL) into the post-training process.
- Synergy: RL unlocks the performance potential of DMD, while DMD regularizes the RL process.
- Result: Images with richer high-frequency details, better structural coherence, and improved semantic alignment.
A Thriving Ecosystem
The Z-Image project is committed to the open-source community. We are thrilled to see rapid adoption and integration across major tools:
- DiffSynth-Studio: Full support for LoRA training, distillation, and low-VRAM inference.
- stable-diffusion.cpp: Enables Z-Image inference on devices with as little as 4GB VRAM.
- ComfyUI: Easy-to-use latent support for official resolutions.
- vLLM-Omni & SGLang: Accelerated inference support for production environments.
Get Started
Ready to experience Z-Image? The models are available now for research and commercial application.
- Z-Image Released: Introducing Z-Image: A Foundation Model Built for Creative Freedom and Fidelity
- Hugging Face: Tongyi-MAI/Z-Image
- ModelScope: Z-Image Collection
- GitHub Repository: Official Codebase
Whether you are generating photorealistic assets, building a custom editing tool, or conducting low-level research, Z-Image provides the foundation you need. Join us in shaping the future of efficient generative AI!